In a previous post we have seen what is a regression line, how we can use it and that its closed form solution is:

where X is the matrix of our features (independent variables) and Y the matrix of the dependent variable.
The computational complexity of inverting this square matrix is nearly cubic.
Even with the computation power ever increasing, this inversion can be prohibitively costly for problems with tens of thousands of independent variables.
Furthermore the matrix cannot be inverted if its determinant is equal to zero.
Many modern machine learning problems take thousands or even millions of dimensions of data to build predictions using hundreds of coefficients. Predicting how an organism’s genome will be expressed, or what the climate will be like in fifty years are examples of such complex problems. We need a different approach.
A family of optimisation algorithms – the gradient descent – have been developed for searching out the space of all possible lines that we might use and finding the one that best fits (approximates) the data.
These algorithms can be used for many applications not only linear regression, for example in neural networks.
But let’s see how this is actually implemented to find the best regression line.
Finding the minimum
Formally, the gradient descent is an optimisation algorithm that can be used to estimate the local minimum of a function.
Recall that the objective of Linear Regression is to minimise the cost function which is the residual sum of squares cost function.
In this case we need to minimise a function of two variables, Beta0 and Beta1:

This is a convex function and we know that the property of its minimum is that the derivative is zero: there’s no rate of change of this function at this point.
And note that for the convex functions there’s only one place where the derivative is zero: the solution to that is going to be unique and we know that it exists.

Using this information, the algorithm is working like this:
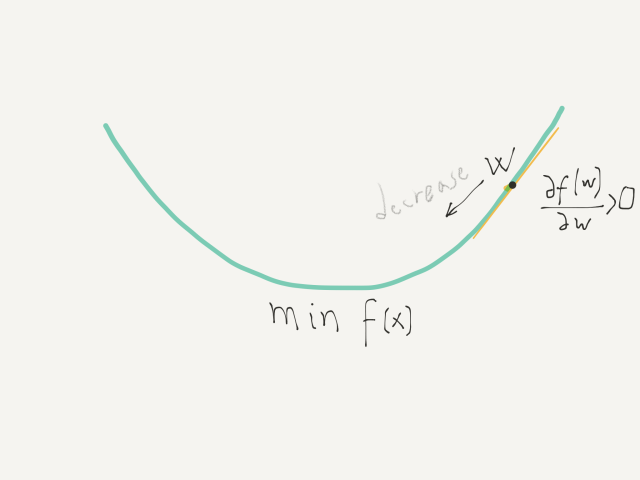
Start on one point of the function, let’s call it w.
Move w until it reaches the minimum.
At every step decide if w should move to the left or to the right. So increase or decrease w.
Can decide this by looking at the derivative of the function: when the derivative is negative, then increase w (and therefore move to the right). When the derivative is positive in this case decrease the value of w (and move to the left).
This optimisation algorithm is often called hill descent (find a minimum) or hill climbing (find a maximum):
while not converged:
w = w - stepsize * derivate (w)
where the parameter stepsize regulates how much to increase or decrease w each time and the function derivate() calculates the derivative.
This is the basic general concept and we can now go into the details.
Choosing the step size
In these algorithms we see that there’s a step size in the formula.
This determines how much we are changing our beta parameters at every iteration of the algorithm.
How do you choose that step size?
There are lots of different choices you can make here and one choice is to keep a fixed step size or constant step size, where – as the name implies – you just set it equal to some constant eta like, for example, eta = 0.1.
The fixed stepsize setting will usually work because in most of the cases these functions are going to be what is called strongly convex. That is just a really well behaving convex function that never flattens out much. And in those settings you will converge using this fixed step size, it just might take longer.
The risks in choosing the appropriate eta is that if it’s too big, you may end up jumping over the optimal and then jumping back and forth quite a number of times.
If it’s too small then it will converge very slowly to the optimal itself.
On the other hand, another common choice is to decrease the step size as the number of iterations increase.
This means that the step size you’re using at iteration i, is equal to some eta over i or
another usual choice is eta over square root of i.
The step size is decreasing with the number of iterations and this makes sense because when I start the algorithm, I’m typically assuming to be decently far from the optimal so I want to take large steps, but as I’m running my algorithm, I’m getting closer and I want to hone in more rapidly to the optimal.
But one thing you have to be careful about is not decreasing the step size too rapidly. Because then you are going again to take a while to converge.
In summary choosing your step size is a bit of an art. But we’ve seen a couple
of examples that are commonly used out there.
For more details about tuning the step size, Sebastian Ruder has an extensive article about optimising the gradient descent algorithm and a paper:
Sebastian Ruder (2016). An overview of gradient descent optimisation algorithms. arXiv preprint arXiv:1609.04747.
When converging?
The other part of the algorithm that we did not yet discuss is how are we going to assess our convergence.
The optimum occurs when the derivative of the function is equal to zero. But what is used in practice is that the derivative – as the algorithm proceed – will get smaller and smaller but it won’t be exactly zero. At some point you want to say that is close enough to the optimum.
As Geoff Hinton said “Early stopping (is) beautiful free lunch” (NIPS 2015 Tutorial slides, slide 63).
Basically we need to specify a threshold epsilon.
When the absolute value of the derivative is less than some epsilon we terminate the algorithm and we consider the current W value as the solution.

How to choose epsilon? It depends on the data, on what the form is the function, on the expected range of gradients and so on.
In practice, we choose epsilon to be very small. We want to see the derivative value decrease until is not changing very much anymore. At that point you know that you’ve converged.
converged = False
while not converged:
...
cost = computeCost(x,y)
if abs(cost - previousCost) < epsilon:
converged = True
else:
previousCost = cost
where computeCost() will be our function calculating the cost function and previousCost the cost calculated in the previous iteration.
Multiple dimensions: gradient
Until this point we’ve talked about functions of just one variable and finding their minimum. But for linear regression using the residual sums of squares as cost function, we have two variables to minimise: Beta zero and Beta one.
Moving to multiple dimensions means we don’t talk about derivatives any more
but about gradients. We have already seen what the gradient is but it’s pretty straightforward: it’s a vector containing the partial derivatives of our function. We take first the partial with respect to beta zero and then the partial with respect to beta one. In theory all the way up to the partial with respect to some beta n.
The gradient descent algorithm is the analogous algorithm to what we have seen just now – the hill descent algorithm for one variable – but – in place of the derivative of the function – we’ve now specified the gradient of the function. And other than that, everything looks exactly the same: at every step we decide in which direction to move, until it converges to the minimum.
For two variables, we move into a 3D-plane.

What we’re doing is we are taking now a vector of parameters and we are updating them all at once. So, it’s just the vector analog of the hill descent algorithm:
def gradient_descent(X, y, beta, stepsize):
converged = False
while not converged:
gradient = derivate (X, beta)
beta = beta - stepsize * gradient
cost = computeCost(X, y, beta)
# did we converge?
if abs(cost - previousCost) < epsilon:
converged = True
return beta
Cost function
One piece that is still missing is the function calculating the cost: computeCost().
Let’s return to the definition of our cost, which is the residual sum of squares of our two parameters, betao, beta1:

Then the function just needs to sum the squared differences between the actual values (y) and the predictions:
import numpy as np def computeCost(features, values, beta): """ Compute the average sum of squared cost Arguments: beta: parameters, list features: input data points, array values : output data points, array Returns: float """ m = len(features) # number of training examples predictions = np.dot(features, beta) sum_of_square_errors = np.square(predictions - values).sum() cost = sum_of_square_errors / (2.0*m) return cost
It uses the numpy library to calculate the product between vectors and also for the square.
Beside that, it is pretty straightforward. You can note that there is an extra 2 on the numerator / divisor and we can see immediately why …
Compute the gradient
The partial derivatives of the cost function above would be :
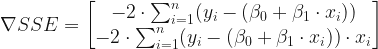
where the part (beta_0 + beta_1 * x) is the predicted value.
By the way, this also explains why we chose SSE as the cost function: the residual sum is convex; and squaring them make the cost function derivable!
The code is also straightforward:
while not converged:
# compute the gradient
h = np.dot(Xfeatures, beta) # hypotesis, predicted value
difference = h - Yvalues # error against prediction
gradient = np.dot(difference, Xfeatures)
# now move beta in the gradient direction
beta = beta - (stepSize * gradient)
Again, we use numpy for the vector product; note also that the multiplication to number 2 is calculated inside computeCost() instead of gradient(). It’s just faster.
Final code
import numpy as np
# === Cost function ===
def computeCost(features, values, beta):
"""
Compute the average sum of squared cost
Arguments:
beta: parameters, list
features: input data points, array
values : output data points, array
Returns:
float
"""
m = len(features) # number of training examples
predictions = np.dot(features, beta)
sum_of_square_errors = np.square(predictions - values).sum()
cost = sum_of_square_errors / (2.0 * m)
return cost
def gradientDescent(Xfeatures, Yvalues, beta,
alpha = 0.0001, tolerance = 0.001, max_iterations = 1000):
"""
Perform gradient descent algorithm
Arguments:
beta: initial parameters, list
Xfeatures: input data points, array
Yvalues : output data points, array
alpha (optional) : step size
tolerance (optional) : epsilon value for convergence
max_iterations (optional): max number of iterations before stopping
Returns:
beta: list of optimised beta parameters
history: pandas Series of costs
"""
# initialization
costHistory = []
previousCost = 0.0
converged = False
i = 0 # iteration counter
m = len(Yvalues) # number of training examples
stepSize = alpha / m # step size increment is constant
# main loop until converged or max iterations reached
while not converged and i <= max_iterations:
h = np.dot(Xfeatures, beta) # hypotesis (prediction)
difference = h - Yvalues # error against hypotesis
gradient = np.dot(difference, Xfeatures) # = x.T.dot(error)/m
# update the beta parameters
beta = beta - (stepSize * gradient)
# calculate the new cost with the new beta parameters
cost = computeCost(Xfeatures, Yvalues, beta)
# update last cost (for convergence check)
if (i > 0):
previousCost = costHistory[-1]
# did we converge?
if abs(cost - previousCost) < tolerance:
converged = True # yes !
print ("*** converged after iterations: ",i)
# Every time it computes the cost for a given list of betas,
# appends it to cost history.
costHistory.append (cost)
i += 1 # next iteration (to check if max is reached)
return beta, pd.Series(costHistory)
The gradientDescent() function will get as parameters an additional max_iterations.
This is because the algorithm something does not converge at all (with e.g. too large step size), therefore we just add a safety stop: when the iterations reach the max we stop anyway.
The function returns the beta parameters but also the cost history so you can plot it / check it.
Tips for Gradient Descent
We have seen that the closed form is not always doable and often we need to use an optimisation algorithm. Its main downside is that we have to choose a step size and a convergence criteria, we have to specify these parameters of the algorithm and is not always easy.
Whereas, of course, if we take the gradient and are able to set it to zero, we don’t have to make any of those choices.
Here are some tips:
- Plot Cost versus Time: Collect and plot the cost values calculated by the algorithm each iteration. The expectation for a well performing gradient descent run is a decrease in cost each iteration. If it does not decrease, try reducing your step size.
- Step size: This learning rate value is a small real number such as 0.1 or 0.0001. Try different values for your problem and see which works best.
- Rescale Inputs: The algorithm will reach the minimum cost faster if the shape of the cost function is not skewed and distorted. You can achieved this by rescaling all of the input variables (X) to the same range, such as [0, 1] or [-1, 1].
Other gradient descent versions
This approach is called also Batch Gradient Descent because the gradient is computed on the complete training batch. Larger is the number of your examples (the Xfeatures), slower will be the algorithm. Thus other approaches use only one sample (Stochastic Gradient) or n samples (mini-batch gradient).
Sebastian Raschka has a nice summary if you are looking for more details.

Pingback: An introduction to logistic regression – Look back in respect
Pingback: Back-propagation for neural network – Look back in respect
Pingback: Multiple Linear Regression – Look back in respect
Pingback: Moneyball: a simple Regression example – Look back in respect