
This shows two simple image-recognition algorithms that can correctly classify pictures as cat or non-cat.
The first is a classic logistic regression while the second – more accurate – is a deep neural network.
You can follow along using the notebook in GitHub also. And this post is part of a series about Machine Learning with Python.
1 – Overview of the data set
The dataset is taken from Andrew Ng’s course on Coursera Introduction to Neural Networks.
The dataset (“data.h5”) contains:
- a training set of m_train images labeled as cat (y=1) or non-cat (y=0)
- a test set of m_test images labeled as cat or non-cat
- each image is of shape (num_px, num_px, 3) where 3 is for the 3 channels (RGB). Thus, each image is square (height = num_px) and (width = num_px).
Let’s get more familiar with the dataset.
import numpy as np
import h5py
# Loading the data (cat/non-cat)
train_dataset = h5py.File('../datasets/train_catvnoncat.h5', "r")
train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # train set features
train_set_y_orig = np.array(train_dataset["train_set_y"][:]) # train set labels
test_dataset = h5py.File('../datasets/test_catvnoncat.h5', "r")
test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # test set features
test_set_y_orig = np.array(test_dataset["test_set_y"][:]) # test set labels
classes = np.array(test_dataset["list_classes"][:]) # the list of classes
train_set_y = train_set_y_orig.reshape((1, train_set_y_orig.shape[0]))
test_set_y = test_set_y_orig.reshape((1, test_set_y_orig.shape[0]))
Each line of train_set_x_orig and test_set_x_orig is an array representing an image.
2 – Data preprocessing
Common steps for pre-processing a new dataset are:
- Figure out the dimensions and shapes of the problem (m_train, m_test, num_px, …)
- Reshape the datasets such that each example is now a vector of size (num_px * num_px * 3, 1)
- “Standardise” the data
Many software bugs in deep learning come from having matrix/vector dimensions that don’t fit. If you can keep your matrix/vector dimensions straight you will go a long way toward eliminating many bugs.
m_train = train_set_x_orig.shape[0]
m_test = test_set_x_orig.shape[0]
num_px = train_set_x_orig.shape[1]
print ("Dataset dimensions:")
print ("Number of training examples: m_train = " + str(m_train))
print ("Number of testing examples: m_test = " + str(m_test))
print ("Height/Width of each image: num_px = " + str(num_px))
print ("Each image is of size: (" + str(num_px) + ", " + str(num_px) + ", 3)")
print ("train_set_x shape: " + str(train_set_x_orig.shape))
print ("train_set_y shape: " + str(train_set_y.shape))
print ("test_set_x shape: " + str(test_set_x_orig.shape))
print ("test_set_y shape: " + str(test_set_y.shape))
[Out]: Dataset dimensions: Number of training examples: m_train = 209 Number of testing examples: m_test = 50 Height/Width of each image: num_px = 64 Each image is of size: (64, 64, 3) train_set_x shape: (209, 64, 64, 3) train_set_y shape: (1, 209) test_set_x shape: (50, 64, 64, 3) test_set_y shape: (1, 50)
For convenience, we now reshape images of shape (num_px, num_px, 3) in a numpy-array of shape (num_px * num_px * 3, 1). After this, our training (and test) dataset is a numpy-array where each column represents a flattened image. There should be m_train (respectively m_test) columns.
A trick when you want to flatten a matrix X of shape (a,b,c,d) to a matrix X_flatten of shape (b*c*d, a) is to use:
X_flatten = X.reshape(X.shape[0], -1).T # X.T is the transpose of X
Applied to our example, it is:
# Reshape the training and test examples
train_set_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[0], -1).T
test_set_x_flatten = test_set_x_orig.reshape(test_set_x_orig.shape[0], -1).T
print ("train_set_x_flatten shape: " + str(train_set_x_flatten.shape))
print ("train_set_y shape: " + str(train_set_y.shape))
print ("test_set_x_flatten shape: " + str(test_set_x_flatten.shape))
print ("test_set_y shape: " + str(test_set_y.shape))
print ("sanity check after reshaping: " + str(train_set_x_flatten[0:5,0]))
[Out]: train_set_x_flatten shape: (12288, 209) train_set_y shape: (1, 209) test_set_x_flatten shape: (12288, 50) test_set_y shape: (1, 50) sanity check after reshaping: [17 31 56 22 33]
To represent color images, the red, green and blue channels (RGB) must be specified for each pixel, and so the pixel value is actually a vector of three numbers ranging from 0 to 255.
One common preprocessing step in machine learning is to center and standardize your dataset, meaning that you substract the mean of the whole numpy array from each example, and then divide each example by the standard deviation of the whole numpy array. But for picture datasets, it is simpler and more convenient and works almost as well to just divide every row of the dataset by 255 (the maximum value of a pixel channel).
Let’s standardise our dataset.
train_set_x = train_set_x_flatten/255. test_set_x = test_set_x_flatten/255.
Logistic Regression
We will build first a logistic regression classifier to recognise the cats.

3 – General Architecture of the learning algorithm
It’s time to design a simple algorithm to distinguish cat images from non-cat images.
The input will be the image transformed into a vector above, normlaised and flattened. The activation function is the sigmoid. If the output is more than 0.5 then it is considered a cat, otherwise not.

Mathematical expression of the algorithm:
For one example 



The cost is then computed by summing over all training examples:

Will use the LogisticRegression module from sklearn.
Key steps:
- Initialize the parameters of the model
- Learn the parameters for the model by minimising the cost
- Use the learned parameters to make predictions (on the test set)
- Analyse the results and conclude
3.1 – Define and fit the logistic regression model
from sklearn.linear_model import LogisticRegression lr = LogisticRegression(C=1000.0, random_state=0) lr.fit(train_set_x.T, train_set_y.T.ravel())
These are the weights that the algorithm fitted to the model:
lr.coef_.shape
(1, 12288)
lr.coef_
array([[ 0.05665593, -0.11370205, -0.04197421, ..., -0.06609142, -0.11239916, 0.15381656]])
lr.intercept_
array([-0.00118436])
The model fitted is therefore:

3.2 – Assess predictions on test data
We can measure the model accuracy using the test set:
Y_prediction = lr.predict(test_set_x.T) Y_prediction.shape
(50,)
print("test accuracy: {} %".format(100 - np.mean(np.abs(Y_prediction - test_set_y)) * 100))
test accuracy: 72.0 %
72% of the test photos have been predicted correctly.
Check the notebook in gitHub to see the mismatched images and how to try with your own image.
Deep Neural Network for Image Classification
Now we will build and apply a deep neural network to the problem.
Dataset
We will use the same “Cat vs non-Cat” dataset as above. The model we had built had 72% test accuracy on classifying cats vs non-cats images. Hopefully, our new model will perform better!
Building the parts of our algorithm
The main steps for building a Neural Network are:
- Define the model structure (such as number of input features) and the hyper-parameters
- Initialise the model’s weights
- Loop for the number of iterations:
– Calculate current loss (forward propagation)
– Calculate current gradient (backward propagation)
– Update parameters (gradient descent) - Use the trained weights to predict the labels
4 – Defining the neural network structure

We will define a deep network with a total of five layers: input, output and three hidden layers.
Each layer has a different number of units.
Defining the architecture of a neural network depends on the training data and the type of classification to perform and it is an art by itself. Defining and re-fining the number of layers, units and all other parameters is called hyperparameters tuning and we will see it in details in a next notebook.
For the moment we hard-code an initial set of parameters.

Detailed Architecture:
– The input is a (64,64,3) image which is flattened to a vector of size (12288,1).
– The corresponding vector: ![[x_0,x_1,...,x_{12287}]^T](https://s0.wp.com/latex.php?latex=%5Bx_0%2Cx_1%2C...%2Cx_%7B12287%7D%5D%5ET&bg=ffffff&fg=111111&s=0&c=20201002)
– You then add a bias term (the intercept b). the result is the linear unit.
– next, we take its ReLU (Rectified Linear Unit) to get the vector: ![[a_0^{[1]}, a_1^{[1]},..., a_{n^{[1]}-1}^{[1]}]^T](https://s0.wp.com/latex.php?latex=%5Ba_0%5E%7B%5B1%5D%7D%2C+a_1%5E%7B%5B1%5D%7D%2C...%2C+a_%7Bn%5E%7B%5B1%5D%7D-1%7D%5E%7B%5B1%5D%7D%5D%5ET&bg=ffffff&fg=111111&s=0&c=20201002)
Each activation vector has a different size depending on the number of units the layer.
– The process is repeated for each hidden layer (in our case three times) and several times (number of iterations), each time calculating the loss and back-propagating appropriate changes in the weights until the wished loss is reached.
– Finally, we take the sigmoid of the final linear unit. If it is greater than 0.5, we classify it to be a cat.
### CONSTANTS DEFINING THE MODEL ####
n_x = train_set_x_flatten.shape[0] # size of input layer
n_y = 1 # size of output layer, will be 0 or 1
# we define a neural network with total 5 layers, x, y and 3 hidden:
# the first hidden has 20 units, second has 7 units and third has 5
nn_layers = [n_x, 20, 7, 5, n_y] # length is 5 (layers)
nn_layers
[Out:] [12288, 20, 7, 5, 1]
5 – Initializing parameters
There are two types of parameters to initialise in a neural network:
– the weight matrices
– the bias vectors
![W^{[i]}](https://s0.wp.com/latex.php?latex=W%5E%7B%5Bi%5D%7D&bg=ffffff&fg=111111&s=0&c=20201002)
![b^{[i]}](https://s0.wp.com/latex.php?latex=b%5E%7B%5Bi%5D%7D&bg=ffffff&fg=111111&s=0&c=20201002)
The weight matrix is initialised with random values while the bias vector as a vector of zeros.
In general, initialising all the weights to zero results in the network failing to break symmetry. This means that every neuron in each layer will learn the same thing and the network is no more powerful than a linear classifier such as logistic regression.
To break symmetry, we initialise the weights randomly. Following random initialisation, each neuron can then proceed to learn a different function of its inputs.
Of course, different initializations lead to different results and poor initialisation can slow down the optimisation algorithm.
One good practice is not to initialise to values that are too large, instead what bring good results are the so-called Xavier (pdf of the paper) or the He (for ReLU activation) initialisations (pdf of the paper).
5.1 – L-layer Neural Network
The initialisation for an L-layer neural network is complicated because there are many weight matrices and bias vectors. Need to make sure that the dimensions match between each layer.
– The model’s structure has L-1 layers using a ReLU activation function followed by an output layer with a sigmoid activation function.
– We will store ![n^{[l]}](https://s0.wp.com/latex.php?latex=n%5E%7B%5Bl%5D%7D&bg=ffffff&fg=111111&s=0&c=20201002)
# FUNCTION: initialise_parameters
def initialise_parameters(layer_dims):
"""
Arguments:
layer_dims -- python array (list) containing the dimensions of each layer in our network
Returns:
parameters -- python dictionary containing your parameters "W1", "b1", ..., "WL", "bL":
Wl -- weight matrix of shape (layer_dims[l], layer_dims[l-1])
bl -- bias vector of shape (layer_dims[l], 1)
"""
parameters = {}
L = len(layer_dims) # number of layers in the network
for l in range(1, L):
parameters['W' + str(l)] = np.random.randn(layer_dims[l], layer_dims[l-1]) / np.sqrt(layer_dims[l-1])
parameters['b' + str(l)] = np.zeros((layer_dims[l], 1))
# unit tests
assert(parameters['W' + str(l)].shape == (layer_dims[l], layer_dims[l-1]))
assert(parameters['b' + str(l)].shape == (layer_dims[l], 1))
return parameters
6 – Forward propagation module
Now that we have initialised our parameters, we will do the forward propagation module.

We will implement some helper functions and then put all together:
– linear_forward: implement the linear part, i.e. the ![Z^{[l]} = W^{[l]}A^{[l-1]} +b^{[l]}](https://s0.wp.com/latex.php?latex=Z%5E%7B%5Bl%5D%7D+%3D+W%5E%7B%5Bl%5D%7DA%5E%7B%5Bl-1%5D%7D+%2Bb%5E%7B%5Bl%5D%7D&bg=ffffff&fg=111111&s=0&c=20201002)
![A^{[0]} = X](https://s0.wp.com/latex.php?latex=A%5E%7B%5B0%5D%7D+%3D+X&bg=ffffff&fg=111111&s=0&c=20201002)
– linear_activation_forward: will add to the linear part the activation where activation will be either ReLU or Sigmoid.
– L-model_forward: will call the [LINEAR -> RELU] 
6.1 – Linear Forward
# FUNCTION: linear_forward
def linear_forward(A, W, b):
"""
Implement the linear part of a layer's forward propagation.
Arguments:
A -- activations from previous layer (or input data): (size of previous layer, number of examples)
W -- weights matrix: numpy array of shape (size of current layer, size of previous layer)
b -- bias vector, numpy array of shape (size of the current layer, 1)
Returns:
Z -- the input of the activation function, also called pre-activation parameter
cache -- a python dictionary containing "A", "W" and "b" ; stored for computing the backward pass efficiently
"""
Z = np.dot(W, A) + b
assert(Z.shape == (W.shape[0], A.shape[1]))
cache = (A, W, b)
return Z, cache
6.2 – Linear-Activation Forward
We will use two activation functions:
– Sigmoid: 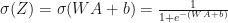
This function returns two items: the activation value “a” and a “cache” that contains “Z” (it’s what we will feed in to the corresponding backward function).
To use it you could just call:
A, activation_cache = sigmoid(Z)
– ReLU: The mathematical formula for ReLu is 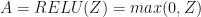
This function returns two items: the activation value “A” and a “cache” that contains “Z” (it’s what we will feed in to the corresponding backward function).
To use it you could just call:
A, activation_cache = relu(Z)
activation functions
# FUNCTION: sigmoid
def sigmoid(Z):
"""
Implements the sigmoid activation in numpy
Arguments:
Z -- numpy array of any shape
Returns:
A -- output of sigmoid(z), same shape as Z
cache -- returns Z as well, useful during backpropagation
"""
A = 1/(1+np.exp(-Z))
cache = Z
return A, cache
def relu(Z):
"""
Implement the RELU function.
Arguments:
Z -- Output of the linear layer, of any shape
Returns:
A -- Post-activation parameter, of the same shape as Z
cache -- a python dictionary containing "A" ; stored for computing the backward pass efficiently
"""
A = np.maximum(0,Z)
assert(A.shape == Z.shape)
cache = Z
return A, cache
Next: Implement the forward propagation of the LINEAR->ACTIVATION layer.
Mathematical relation is: ![A^{[l]} = g(Z^{[l]}) = g(W^{[l]}A^{[l-1]} +b^{[l]})](https://s0.wp.com/latex.php?latex=A%5E%7B%5Bl%5D%7D+%3D+g%28Z%5E%7B%5Bl%5D%7D%29+%3D+g%28W%5E%7B%5Bl%5D%7DA%5E%7B%5Bl-1%5D%7D+%2Bb%5E%7B%5Bl%5D%7D%29&bg=ffffff&fg=111111&s=0&c=20201002)
# FUNCTION: linear_activation_forward
def linear_activation_forward(A_prev, W, b, activation):
"""
Implement the forward propagation for the LINEAR->ACTIVATION layer
Arguments:
A_prev -- activations from previous layer (or input data): (size of previous layer, number of examples)
W -- weights matrix: numpy array of shape (size of current layer, size of previous layer)
b -- bias vector, numpy array of shape (size of the current layer, 1)
activation -- the activation to be used in this layer, stored as a text string: "sigmoid" or "relu"
Returns:
A -- the output of the activation function, also called the post-activation value
cache -- a python dictionary containing "linear_cache" and "activation_cache";
stored for computing the backward pass efficiently
"""
Z, linear_cache = linear_forward(A_prev, W, b)
if activation == "sigmoid":
A, activation_cache = sigmoid(Z)
elif activation == "relu":
A, activation_cache = relu(Z)
assert (A.shape == (W.shape[0], A_prev.shape[1]))
cache = (linear_cache, activation_cache)
return A, cache
Note: In deep learning, the “[LINEAR->ACTIVATION]” computation is counted as a single layer in the neural network, not two layers.
L-Layer Model
Now we put all together, using the helper functions:
the (`linear_activation_forward` with RELU) L-1 times, then follows that with one `linear_activation_forward` with SIGMOID.
# FUNCTION: L_model_forward
def L_model_forward(X, parameters):
"""
Implement forward propagation for the [LINEAR->RELU]*(L-1)->LINEAR->SIGMOID computation
Arguments:
X -- data, numpy array of shape (input size, number of examples)
parameters -- output of initialize_parameters_deep()
Returns:
AL -- last post-activation value
caches -- list of caches containing:
every cache of linear_relu_forward() (there are L-1 of them, indexed from 0 to L-2)
the cache of linear_sigmoid_forward() (there is one, indexed L-1)
"""
caches = []
A = X
L = len(parameters) // 2 # number of layers in the neural network
# Implement [LINEAR -> RELU]*(L-1). Add "cache" to the "caches" list.
for l in range(1, L):
A_prev = A
w_l = parameters['W' + str(l)]
b_l = parameters['b' + str(l)]
A, cache = linear_activation_forward(A_prev, w_l, b_l, activation = "relu")
caches.append(cache)
# Implement LINEAR -> SIGMOID. Add "cache" to the "caches" list.
w_L = parameters['W' + str(L)]
b_L = parameters['b' + str(L)]
Yhat, cache = linear_activation_forward(A, w_L, b_L, activation = "sigmoid")
caches.append(cache)
assert(Yhat.shape == (1,X.shape[1]))
return Yhat, caches
Great! Now we have a full forward propagation that takes the input X and outputs a row vector ![A^{[L]}](https://s0.wp.com/latex.php?latex=A%5E%7B%5BL%5D%7D&bg=ffffff&fg=111111&s=0&c=20201002)
7 – Cost function
Now we need to compute the cost, because we want to check if our model is actually learning.
Next: Compute the cross-entropy cost J, using the following formula:
![-\frac{1}{m} \sum\limits_{i = 1}^{m} (y^{(i)}\log\left(a^{[L] (i)}\right) + (1-y^{(i)})\log\left(1- a^{[L](i)}\right))](https://s0.wp.com/latex.php?latex=-%5Cfrac%7B1%7D%7Bm%7D+%5Csum%5Climits_%7Bi+%3D+1%7D%5E%7Bm%7D+%28y%5E%7B%28i%29%7D%5Clog%5Cleft%28a%5E%7B%5BL%5D+%28i%29%7D%5Cright%29+%2B+%281-y%5E%7B%28i%29%7D%29%5Clog%5Cleft%281-+a%5E%7B%5BL%5D%28i%29%7D%5Cright%29%29+&bg=ffffff&fg=111111&s=0&c=20201002)
# FUNCTION: compute_cost
def compute_cost(Yhat, Y):
"""
Implement the cross-entropy cost function
Arguments:
Yhat -- probability vector corresponding to the label predictions, shape (1, number of examples)
Y -- true "label" vector (for example: containing 0 if non-cat, 1 if cat), shape (1, number of examples)
Returns:
cost -- cross-entropy cost
"""
m = Y.shape[1]
# Compute loss from AL and Y.
logprobs = np.dot(Y, np.log(Yhat).T) + np.dot((1-Y), np.log(1-Yhat).T)
cost = (-1./m) * logprobs
cost = np.squeeze(cost) # To make sure your cost's shape is what we expect (e.g. this turns [[17]] into 17).
assert(cost.shape == ())
return cost
8 – Backward propagation module
Now we will implement the backward function for the whole network.

Just like with forward propagation, we will implement helper functions for backpropagation. Remember that back propagation is used to calculate the gradient of the loss function with respect to the parameters.
You can see more about backpropagation in my previous post:
Now, similar to forward propagation, we are going to build the backward propagation in three steps:
– linear backward
– LINEAR -> ACTIVATION backward where ACTIVATION computes the derivative of either the ReLU or sigmoid activation
– [LINEAR -> RELU]
Reminder:

The purple blocks represent the forward propagation, and the red blocks represent the backward propagation.
8.1 – Linear backward
For layer l, the linear part is: ![Z^{[l]} = W^{[l]} A^{[l-1]} + b^{[l]}](https://s0.wp.com/latex.php?latex=Z%5E%7B%5Bl%5D%7D+%3D+W%5E%7B%5Bl%5D%7D+A%5E%7B%5Bl-1%5D%7D+%2B+b%5E%7B%5Bl%5D%7D&bg=ffffff&fg=111111&s=0&c=20201002)
Now we need to compute the three derivatives ![(dW^{[l]}, db^{[l]}, dA^{[l]})](https://s0.wp.com/latex.php?latex=%28dW%5E%7B%5Bl%5D%7D%2C+db%5E%7B%5Bl%5D%7D%2C+dA%5E%7B%5Bl%5D%7D%29&bg=ffffff&fg=111111&s=0&c=20201002)
![dZ^{[l]} = \frac{\partial \mathcal{L} }{\partial Z^{[l]}}](https://s0.wp.com/latex.php?latex=dZ%5E%7B%5Bl%5D%7D+%3D+%5Cfrac%7B%5Cpartial+%5Cmathcal%7BL%7D+%7D%7B%5Cpartial+Z%5E%7B%5Bl%5D%7D%7D&bg=ffffff&fg=111111&s=0&c=20201002)
![dW^{[l]} = \frac{\partial \mathcal{L} }{\partial W^{[l]}} = \frac{1}{m} dZ^{[l]} A^{[l-1] T}](https://s0.wp.com/latex.php?latex=dW%5E%7B%5Bl%5D%7D+%3D+%5Cfrac%7B%5Cpartial+%5Cmathcal%7BL%7D+%7D%7B%5Cpartial+W%5E%7B%5Bl%5D%7D%7D+%3D+%5Cfrac%7B1%7D%7Bm%7D+dZ%5E%7B%5Bl%5D%7D+A%5E%7B%5Bl-1%5D+T%7D+&bg=ffffff&fg=111111&s=0&c=20201002)
![db^{[l]} = \frac{\partial \mathcal{L} }{\partial b^{[l]}} = \frac{1}{m} \sum_{i = 1}^{m} dZ^{[l](i)}](https://s0.wp.com/latex.php?latex=db%5E%7B%5Bl%5D%7D+%3D+%5Cfrac%7B%5Cpartial+%5Cmathcal%7BL%7D+%7D%7B%5Cpartial+b%5E%7B%5Bl%5D%7D%7D+%3D+%5Cfrac%7B1%7D%7Bm%7D+%5Csum_%7Bi+%3D+1%7D%5E%7Bm%7D+dZ%5E%7B%5Bl%5D%28i%29%7D&bg=ffffff&fg=111111&s=0&c=20201002)
![dA^{[l-1]} = \frac{\partial \mathcal{L} }{\partial A^{[l-1]}} = W^{[l] T} dZ^{[l]}](https://s0.wp.com/latex.php?latex=dA%5E%7B%5Bl-1%5D%7D+%3D+%5Cfrac%7B%5Cpartial+%5Cmathcal%7BL%7D+%7D%7B%5Cpartial+A%5E%7B%5Bl-1%5D%7D%7D+%3D+W%5E%7B%5Bl%5D+T%7D+dZ%5E%7B%5Bl%5D%7D+&bg=ffffff&fg=111111&s=0&c=20201002)
# FUNCTION: linear_backward
def linear_backward(dZ, cache):
"""
Implement the linear portion of backward propagation for a single layer (layer l)
Arguments:
dZ -- Gradient of the cost with respect to the linear output (of current layer l)
cache -- tuple of values (A_prev, W, b) coming from the forward propagation in the current layer
Returns:
dA_prev -- Gradient of the cost with respect to the activation (of the previous layer l-1), same shape as A_prev
dW -- Gradient of the cost with respect to W (current layer l), same shape as W
db -- Gradient of the cost with respect to b (current layer l), same shape as b
"""
A_prev, W, b = cache
m = A_prev.shape[1]
dW = (1./m) * np.dot(dZ, A_prev.T)
db = (1./m) * np.sum(dZ, axis=1, keepdims=True)
dA_prev = np.dot(W.T, dZ)
assert (dA_prev.shape == A_prev.shape)
assert (dW.shape == W.shape)
assert (db.shape == b.shape)
return dA_prev, dW, db
8.2 – Linear-Activation backward
Next, we will create a function that merges the two helper functions: `linear_backward` and the backward step for the activation:
– `sigmoid_backward`: Implements the backward propagation for SIGMOID unit.
– `relu_backward`: Implements the backward propagation for RELU unit.
If g(.) is the activation function, `sigmoid_backward` and `relu_backward` compute ![dZ^{[l]} = dA^{[l]} * g'(Z^{[l]})](https://s0.wp.com/latex.php?latex=dZ%5E%7B%5Bl%5D%7D+%3D+dA%5E%7B%5Bl%5D%7D+%2A+g%27%28Z%5E%7B%5Bl%5D%7D%29+&bg=ffffff&fg=111111&s=0&c=20201002)
def sigmoid_backward(dA, cache):
"""
Implement the backward propagation for a single SIGMOID unit.
Arguments:
dA -- post-activation gradient, of any shape
cache -- 'Z' where we store for computing backward propagation efficiently
Returns:
dZ -- Gradient of the cost with respect to Z
"""
Z = cache
s = 1/(1+np.exp(-Z))
dZ = dA * s * (1-s)
assert (dZ.shape == Z.shape)
return dZ
def relu_backward(dA, cache):
"""
Implement the backward propagation for a single RELU unit.
Arguments:
dA -- post-activation gradient, of any shape
cache -- 'Z' where we store for computing backward propagation efficiently
Returns:
dZ -- Gradient of the cost with respect to Z
"""
Z = cache
dZ = np.array(dA, copy=True) # just converting dz to a correct object.
# When z <= 0, you should set dz to 0 as well.
dZ[Z <= 0] = 0 assert (dZ.shape == Z.shape) return dZ
# FUNCTION: linear_activation_backward def linear_activation_backward(dA, cache, activation): """ Implement the backward propagation for the LINEAR->ACTIVATION layer.
Arguments:
dA -- post-activation gradient for current layer l
cache -- tuple of values (linear_cache, activation_cache) we store for computing backward propagation efficiently
activation -- the activation to be used in this layer, stored as a text string: "sigmoid" or "relu"
Returns:
dA_prev -- Gradient of the cost with respect to the activation (of the previous layer l-1), same shape as A_prev
dW -- Gradient of the cost with respect to W (current layer l), same shape as W
db -- Gradient of the cost with respect to b (current layer l), same shape as b
"""
linear_cache, activation_cache = cache
if activation == "relu":
dZ = relu_backward(dA, activation_cache)
elif activation == "sigmoid":
dZ = sigmoid_backward(dA, activation_cache)
dA_prev, dW, db = linear_backward(dZ, linear_cache)
return dA_prev, dW, db
8.3 – L-Model Backward
Recall that when we implemented the `L_model_forward` function, at each iteration, we stored a cache which contains (X,W,b, and z). In the back propagation module, we will use those variables to compute the gradients. Therefore, in the `L_model_backward` function, we will iterate through all the hidden layers backward, starting from layer L. On each step, we will use the cached values for layer l to back-propagate through layer l.
# FUNCTION: L_model_backward
def L_model_backward(Yhat, Y, caches):
"""
Implement the backward propagation for the [LINEAR->RELU] * (L-1) -> LINEAR -> SIGMOID group
Arguments:
AL -- probability vector, output of the forward propagation (L_model_forward())
Y -- true "label" vector (containing 0 if non-cat, 1 if cat)
caches -- list of caches containing:
every cache of linear_activation_forward() with "relu" (it's caches[l], for l in range(L-1) i.e l = 0...L-2)
the cache of linear_activation_forward() with "sigmoid" (it's caches[L-1])
Returns:
grads -- A dictionary with the gradients
grads["dA" + str(l)] = ...
grads["dW" + str(l)] = ...
grads["db" + str(l)] = ...
"""
grads = {}
L = len(caches) # the number of layers
m = Yhat.shape[1]
Y = Y.reshape(Yhat.shape) # after this line, Y is the same shape as AL
# Initializing the backpropagation
dAL = - (np.divide(Y, Yhat) - np.divide(1 - Y, 1 - Yhat)) # derivative of cost with respect to AL
# Lth layer (SIGMOID -> LINEAR) gradients. Inputs: "AL, Y, caches". Outputs: "grads["dAL"], grads["dWL"], grads["dbL"]
current_cache = caches[L-1]
grads["dA" + str(L)], grads["dW" + str(L)], grads["db" + str(L)] = linear_activation_backward(dAL, current_cache, activation = "sigmoid")
for l in reversed(range(L-1)):
# lth layer: (RELU -> LINEAR) gradients.
# Inputs: "grads["dA" + str(l + 2)], caches". Outputs: "grads["dA" + str(l + 1)] , grads["dW" + str(l + 1)] , grads["db" + str(l + 1)]
current_cache = caches[l]
dA_prev_temp, dW_temp, db_temp = linear_activation_backward(grads["dA"+str(l+2)], current_cache, activation = "relu")
grads["dA" + str(l + 1)] = dA_prev_temp
grads["dW" + str(l + 1)] = dW_temp
grads["db" + str(l + 1)] = db_temp
return grads
8.4 – Update Parameters
In this section we will update the parameters of the model, using gradient descent:
![W^{[l]} = W^{[l]} - \alpha \text{ } dW^{[l]}](https://s0.wp.com/latex.php?latex=W%5E%7B%5Bl%5D%7D+%3D+W%5E%7B%5Bl%5D%7D+-+%5Calpha+%5Ctext%7B+%7D+dW%5E%7B%5Bl%5D%7D+&bg=ffffff&fg=111111&s=0&c=20201002)
![b^{[l]} = b^{[l]} - \alpha \text{ } db^{[l]}](https://s0.wp.com/latex.php?latex=b%5E%7B%5Bl%5D%7D+%3D+b%5E%7B%5Bl%5D%7D+-+%5Calpha+%5Ctext%7B+%7D+db%5E%7B%5Bl%5D%7D+&bg=ffffff&fg=111111&s=0&c=20201002)
where 
# FUNCTION: update_parameters
def update_parameters(parameters, grads, learning_rate):
"""
Update parameters using gradient descent
Arguments:
parameters -- python dictionary containing your parameters
grads -- python dictionary containing your gradients, output of L_model_backward
Returns:
parameters -- python dictionary containing your updated parameters
parameters["W" + str(l)] = ...
parameters["b" + str(l)] = ...
"""
L = len(parameters) // 2 # number of layers in the neural network
# Update rule for each parameter. Use a for loop.
for l in range(L):
parameters["W"+str(l+1)] = parameters["W"+str(l+1)] - learning_rate * grads["dW" + str(l+1)]
parameters["b"+str(l+1)] = parameters["b"+str(l+1)] - learning_rate * grads["db" + str(l+1)]
return parameters
9 – L-layer Neural Network
Now we can put together all the functions to build an L-layer neural network with this structure:
nn_layers
[12288, 20, 7, 5, 1]
# FUNCTION: L_layer_model
def L_layer_model(X, Y, layers_dims, learning_rate = 0.0075, num_iterations = 3000, print_cost=False):
"""
Implements a L-layer neural network: [LINEAR->RELU]*(L-1)->LINEAR->SIGMOID.
Arguments:
X -- data, numpy array of shape (number of examples, num_px * num_px * 3)
Y -- true "label" vector (containing 0 if cat, 1 if non-cat), of shape (1, number of examples)
layers_dims -- list containing the input size and each layer size, of length (number of layers + 1).
learning_rate -- learning rate of the gradient descent update rule
num_iterations -- number of iterations of the optimization loop
print_cost -- if True, it prints the cost every 100 steps
Returns:
parameters -- parameters learnt by the model. They can then be used to predict.
"""
costs = [] # keep track of cost
# Parameters initialization.
parameters = initialise_parameters(layers_dims)
# Loop (gradient descent)
for i in range(0, num_iterations):
# Forward propagation: [LINEAR -> RELU]*(L-1) -> LINEAR -> SIGMOID.
AL, caches = L_model_forward(X, parameters)
# Compute cost.
cost = compute_cost(AL, Y)
# Backward propagation.
grads = L_model_backward(AL, Y, caches)
# Update parameters.
parameters = update_parameters(parameters, grads, learning_rate)
# Print the cost every 100 training example
if print_cost and i % 100 == 0:
print ("Cost after iteration %i: %f" %(i, cost))
if print_cost and i % 100 == 0:
costs.append(cost)
# plot the cost
plt.plot(np.squeeze(costs))
plt.ylabel('cost')
plt.xlabel('iterations (per tens)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
return parameters
We can then train the model as a 5-layer neural network.
The cost should decrease on every iteration.
np.random.seed(1) fit_params = L_layer_model(train_set_x, train_set_y, nn_layers, num_iterations = 2500, print_cost = True)
Cost after iteration 0: 0.771749 Cost after iteration 100: 0.672053 ... Cost after iteration 2400: 0.092878

10. Results analysis
Now we can check the performance of the trained network by predicting the results of the test set and comparing them with the actual labels.
def predict(X, y, parameters):
"""
This function is used to predict the results of a L-layer neural network.
Arguments:
X -- data set of examples you would like to label
parameters -- parameters of the trained model
Returns:
p -- predictions for the given dataset X
"""
m = X.shape[1]
n = len(parameters) // 2 # number of layers in the neural network
p = np.zeros((1,m))
# Forward propagation
probas, caches = L_model_forward(X, parameters)
# convert probs to 0/1 predictions
for i in range(0, probas.shape[1]):
if probas[0,i] > 0.5:
p[0,i] = 1
else:
p[0,i] = 0
# print results
print("Accuracy: " + str(np.sum((p == y)/m)))
return p
pred_train = predict(train_set_x, train_set_y, fit_params)
Accuracy: 0.985645933014
pred_test = predict(test_set_x, test_set_y, fit_params)
Accuracy: 0.8
Congrats! It seems that this 5-layer neural network has better performance (80%) than the logistic regression model (72%) on the same test set.
This is good performance for this task.
Even higher accuracy could be obtained, by systematically searching for better hyperparameters (learning_rate, layers_dims, num_iterations) and other techniques such as regularisation, that we can see in the next notebook.
With logistic regression we had 14 misses in the test set, out of 50. With the neural network we have 10 misses.
Note: this post is part of a series about Machine Learning with Python.
Bibliography:
– Andrew Ng’s deep learning course
– Tutorial: implement a neural network from scratch
– Image normalisation

Pingback: "Dataset (data.h5) contenant des images CAT ou non CAT Télécharger" Code Réponse - Coder les réponses
Pingback: Grâce à l'IA, les chercheurs pourraient prédire l'avenir de manière inédite - Essentiel Xibar
Pingback: Grâce à l'IA, les chercheurs ont pu prédire l'avenir d'une manière sans précédent
Hi Mashimo,
I have a question regarding Cat Vs Non-Cat dataset. How do we decide how many samples do we need for a non-cat dataset? Should it be the same as the number of cat samples or is there any method to determine this? Thanks
These kind of algorithms generally work best when the training set has balanced classes, i.e. the cats and non-cats examples are roughly the same in size. In an example like this – where the most important criteria is the general accuracy – it probably doesn’t matter too much: it would work well also with a class having 80% of examples and the other represented by 20%.
In other problems – like classifying a rare disease – the risk of having a strongly unbalanced set is that those cases will be treated as outliers. Looking at other metrics lice accuracy, sensitivity or specificity can help to detect it. Methods to address unbalanced sets include over-sampling the minority class or specially tune the weights in the algorithm.
Hi Mashimo,
I have a question regarding Cat Vs Non-Cat dataset. How do we decide how many samples do we need for a non-cat dataset? Should it be the same as the number of cat samples or is there any method to determine this? Thanks
why do you divide the x set by 255 and not the y set? seems like an error.
Yes, you are right. Preprocessing should be applied to both sets. Thanks.
Hallo Yasmin,
sure: the datasets can be found in this GitHub repository: https://github.com/Mashimo/datascience/tree/master/datasets
– train_catvnoncat.h5 (https://github.com/Mashimo/datascience/raw/master/datasets/train_catvnoncat.h5) is the training set and
– test_catvnoncat.h5 (https://github.com/Mashimo/datascience/raw/master/datasets/test_catvnoncat.h5) is the testing set.
There is a “download” button on the right side.
Thank you ^_^
Thank you very much. It took a long time to find this dataset. I can not find this dataset in Coursera.
Thanks for this useful tutorial, I need the dataset to apply the code, could you please send it to me or tell me where I can find it?
I’m looking forward to your response.
Yasmin