Azure ML (Machine Learning) Studio is an interactive environment from Microsoft to build predictive analytics solutions.
You can upload your data or use the Azure cloud and via a drag-and-drop interface you can combine existing machine learning algorithms – or your own scripts, in several languages – to build and test a data science pipeline.
Eventually, the final model can be deployed as a web service for e.g. Excel or custom apps.
If you are already using the Azure solutions, it offers a valuable add-on for machine learning. Especially if you need a quick way to analyse an dataset and evaluate a model.
This is what Gartner says about Azure ML Studio in its 2018 “Magic Quadrant for Data Science and Machine-Learning Platforms”:
Microsoft remains a Visionary.
Its position in this regard is attributable to low scores for market responsiveness and product viability, as Azure Machine Learning Studio’s cloud-only nature limits its usability for the many advanced analytic use cases that require an on-premises option.
Note: I have no affiliation with Microsoft nor I am payed by them. I am just looking into the main tools available for machine learning.
We will see how to create and build a regression model based on the Autos dataset that we already used earlier.
You can follow up this experiment, directly from Azure ML Studio.
Start with a dataset
It’s very easy to do a first experiment with it: all you need is a web browser and to register an account at Microsoft Live.
Open a browser (it works with non-Microsoft ones too) and browse to Azure ML Studio. Then sign in using the Microsoft account associated with your Azure account.
Create a new blank experiment.
Now you can add a dataset, e.g. by uploading it from a local file. This effectively acts as a pandas read_csv command and load all the data into a data frame. In the example, there were two datasets available: autos.csv which contains a make-id column (a numeric code) that links to the manufacturer listed in the separate file makes.csv.
Note that the datasets are depicted as little boxes in the graphical panel: those are modules. Azure ML Studio has a set of available and pre-defined modules, providing a specific purpose and each module has associated properties and context menus with additional functionalities. One of the functionalities is Visualize: inside Azure ML Studio, you can explore the dataset with an easy visualisation feature, from where you can check each feature via the statistical measures or charts:



Clean the data
The power of Azure ML Studio is that you can connect the modules between them; in this way the output of one (or more) module will be the input of the other module.
One of the available module is the Join Data module which – well – allows to join two datasets: just need to connect the output of the autos.csv dataset to one of the inputs of the Join Data module, then connect the output of the makes.csv dataset to the other input of the Join Data module.
In the property panel, you can decide which field to join. This will be like running a SQL command on the dataset:

You can add more modules, like you can see in the studio, for example I added several modules to clean the dataset, such as the module Group Categorical Values to make the number-of-cilinders a category, the Clean Missing Data + Remove Duplicate Rows to remove the entire row when there is one value missing in one of the remaining column.
You can also add ad hoc code. Here we see as example a Python script to detect outliers:

Now we have a clean dataset and we can visualise it again. You can see now there are less columns, less rows and the cylinders feature is now a feature with 3 categories.

Prepare the target variable
The overall goal of the data exploration is to find a way to predict a car’s price based on its features, but the skewed nature of the price distribution will make this difficult. It may be easier to fit the more balanced logarithmic distribution price values to a predictive model.
The Apply Math Operation module can be added to create a new calculated column in the dataset that contains the natural log of the price:

One important last step is to split the dataset into a training and a testing set, one used to train the model and one to evaluate it.
Will randomly split the original dataset into a 70-30% ratio using the Split Data module:

Train and evaluate the model
There are many available modules to train a model. We use the modules Linear Regression and the Train Model. The former is used to define which kind of model (e.g. ordinary lest squares) and its hyper-parameters (e.g. the regularisation) while the latter will do the train part.
Its inputs are the model defined, the training data and which one is the target variable.
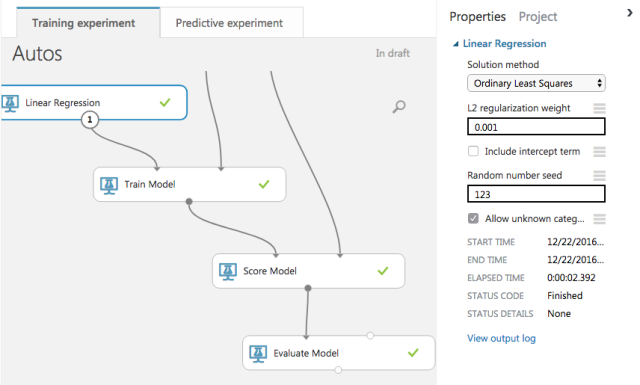
Finally the modules Score Model and Evaluate Model can be used to test the model using the test dataset. Its inputs are the trained model and the test dataset that was kept separated.
The output of the modules are the results:

Publish the model as a Web Service
Now that we have created the regression model, it can be used to make predictions. Directly from the Azure ML Studio by entering manually the input parameters:
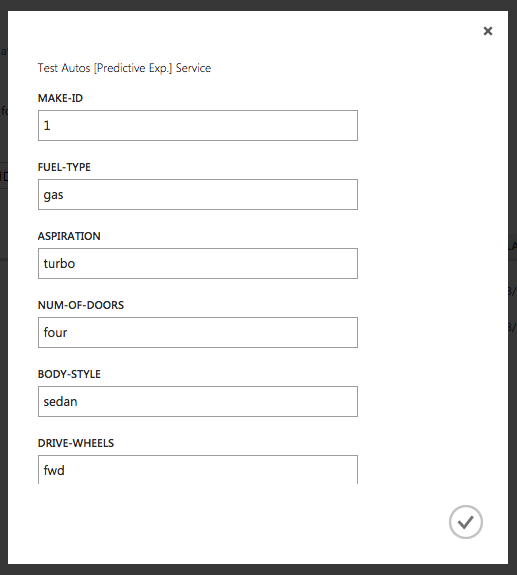
And get the result:

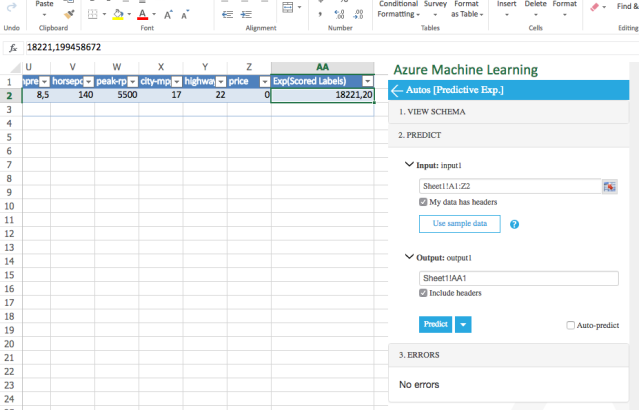
Another possibility would be to publish the experiment as a web service and use it from a client application, such as an Excel spreadsheet (there is a free Azure Machine Learning add-on).
This is done by just clicking on the Set up a web service; this will copy the pipeline into a new panel; and finally you can Deploy the Web service: you get an API key and an URL that can be pasted e.g. into an Excel Online (OneDrive Live) workbook: